Last edited by  王鹏举
王鹏举
Spark简单使用心得
开发环境
id关联库项目中用Spark干了什么
- 融合
- qcc源库中有人的pid和公司的fid
- 在tb_person表中保存(pid, ppid)的关系
- 在tb_company表中保存(fid, digest)的关系
- 在融合库中,保存人企关系,里面保存人的ppid和公司的digest
- 读5个亿级别大表(数据量7亿),写4亿数据,关联8次,排序3次,25分钟
- 之后
load data进数据库
- 事后检测/修复
- 数据融合时,检测是否所有的pid都能关联到ppid
- 筛选错误数据,快速确定数据量,导出爬虫任务重新采集
- 筛选关联库较工商库少的数据,导出爬虫任务
- 统计
- 将digest与hudi表进行关联,统计不同企业类型不同经营状态的数量,Spark直接将统计数据写入数据库(因为数据量小所以可以直接写)
- 交互式分析数据
概念理解
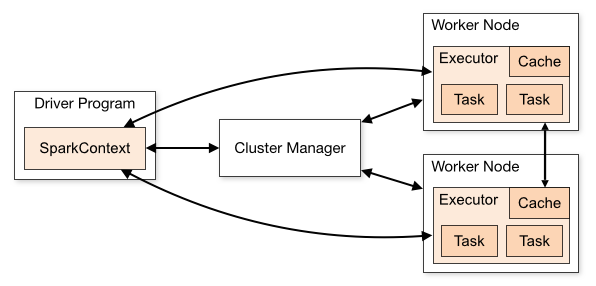
Spark Application
![]()
RDD
-
RDD
partitionspartitionerdependenciescomputepreferredLocations
-
transform, action
- 早期API
- 处理非结构化数据
DataFrame/Dataset
-
RDD提供的算子太抽象,难以优化
-
DataFrame 即 Dataset[Row]
- 带schema,甚至推断schema,可以优化 (Tungsten)
-
DataSet提供DSL算子,可以优化 (Catalyst)
- 类型安全
使用心得
- 能配置化的东西配置化 (pureconfig)
- 多使用
Dataset的DSL方法,而非SQL语句
参考
 王鹏举
王鹏举