kafka
定义
Kafka是一款分布式消息发布和订阅系统,它的特点是高性能、高吞吐量。最早设计的目的是作为LinkedIn的活动流和运营数据的处理管道。
这些数据主要是用来对用户做用户画像分析以及服务器性能数据的一些监控。所以kafka一开始设计的目标就是作为一个分布式、高吞吐量的消息系统,
所以适合运用在大数据传输场景。WHY
解耦合
削峰填谷
冗余(实时和离线)和扩展
高吞吐高并发
送达保证
异步通信基本概念
【Topic】
在Kafka中,使用一个类别属性来划分数据的所属类,划分数据的这个类称为topic。如果把Kafka看做为一个数据库,topic可以理解为数据库中的一张表,topic的名字即为表名。
【Broker】
* Kafka 集群包含一个或多个服务器,服务器节点称为broker。
* broker存储topic的数据。如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
* 如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
* 如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
【Partition】
topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,
partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
【Partition offset】
每条消息都有一个当前Partition下唯一的64字节的offset,它指明了这条消息的起始位置。
【Replicas of partition】
副本是一个分区的备份。副本不会被消费者消费,副本只用于防止数据丢失,即消费者不从为follower的partition中消费数据,而是从为leader的partition中读取数据。
【Producer】
生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。
生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
【Consumer】
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
【Leader】
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
【Follower】
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。
当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
* 当消费者的数目超过topic的partition数目时,后来的消费者将消费不到Kafka中的数据。因为在Kafka给每一个消费者消费者至少分配一个partition,
一旦partition都被指派给消费者了,新来的消费者将不会再分配partition。即一个partition只能分配给一个消费者,一个消费者可以消费多个partition。日常使用样例
kafka_ic_spider_data:
class: kafka.KafkaReader
init:
servers: "10.8.6.230:9092,10.8.6.231:9092,10.8.6.232:9092"
topics: "ic-spider-data"
group: '{group}'
from_beginning: True # 从头消费
extract_collie_result: true # collie_result添加到信息中
max_poll_records: 200 # 批的大小(默认500)
max_poll_interval_ms: 600000 # 处理一个批次的数据最大时间(默认300000)
参数举例
fetch_min_bytes(int) - 服务器为获取请求而返回的最小数据量,否则请等待
fetch_max_wait_ms(int) - 如果没有足够的数据立即满足fetch_min_bytes给出的要求,服务器在回应提取请求之前将阻塞的最大时间量(以毫秒为单位)
fetch_max_bytes(int) - 服务器应为获取请求返回的最大数据量。这不是绝对最大值,如果获取的第一个非空分区中的第一条消息大于此值,
则仍将返回消息以确保消费者可以取得进展。注意:使用者并行执行对多个代理的提取,因此内存使用将取决于包含该主题分区的代理的数量。
支持的Kafka版本> = 0.10.1.0。默认值:52428800(50 MB)。
enable_auto_commit(bool) - 如果为True,则消费者的偏移量将在后台定期提交。默认值:True。
设置为false, 并在每处理完一条数据后手动提交offset。
max_poll_records(int) - poll()单次调用中返回的最大记录数。默认值:500
max_poll_interval_ms(int) - poll()使用使用者组管理时的调用之间的最大延迟 。这为消费者在获取更多记录之前可以闲置的时间量设置了上限。
如果 poll()在此超时到期之前未调用,则认为使用者失败,并且该组将重新平衡以便将分区重新分配给另一个成员。默认300000
consumer_timeout_ms (int) – number of milliseconds to block during message iteration before raising StopIteration
(i.e., ending the iterator). Default block forever [float('inf')].自建kafka的操作命令
0.列举所有的topic
/opt/cloudera/parcels/KAFKA-3.0.0-1.3.0.0.p0.40/lib/kafka/bin/kafka-topics.sh --zookeeper 192.168.109.49:2181/kafka --list
1.新建
kafka-topics.sh --zookeeper 192.168.109.49:2181/kafka --create --replication-factor 3 --partitions 40 --topic collie-fetch-img
2.删除
kafka-topics.sh --zookeeper 192.168.109.49:2181/kafka --delete --topic collie-fetch-img
3.详情
kafka-topics.sh --zookeeper 192.168.109.49:2181/kafka --describe --topic collie-fetch-img
4.修改分区数
kafka-topics.sh --zookeeper 192.168.109.49:2181/kafka --alter --topic collie-fetch-img --partitions 100
5.group查看
kafka-consumer-groups.sh --bootstrap-server 192.168.109.55:9092 --group collie_fetch_img-4b78de0a526511ea8adbf750b2f096d1 --describe
# group重置到最新
kafka-consumer-groups.sh --bootstrap-server 192.168.109.55:9092 --group collie_fetch_img-4b78de0a526511ea8adbf750b2f096d1 --topic collie-fetch-img --reset-offsets --to-latest --execute
6.内容查看--from-beginning
kafka-console-consumer.sh --bootstrap-server 192.168.109.55:9092 --topic collie-fetch-img
kafka-console-consumer.sh --bootstrap-server 192.168.109.55:9092 --topic collie-fetch-img --from-beginning
7.查看有那些 group ID 正在进行消费
kafka-consumer-groups.sh --new-consumer --bootstrap-server 192.168.109.55:9092 --list
8.查看指定group.id 的消费者消费情况
kafka-consumer-groups.sh --new-consumer --bootstrap-server 192.168.109.55:9092 --group collie_sync_mysql-7d9354bea3a8e0d390a7f8e46ca47cfb --describerebanalce
https://www.cnblogs.com/chanshuyi/p/kafka_rebalance_quick_guide.html
假设某个组下有20个consumer实例,该组订阅了一个有着100个分区的topic。正常情况下,Kafka会为每个consumer平均分配5个分区。
这个分配过程就被称为rebalance。当consumer成功地执行rebalance后,组订阅topic的每个分区只会分配给组内的一个consumer实例.
1.10人20椅子,1人2椅,
所有人坐好才可以吃饭,
可以自己换,不能与人换。我要换座位,所有人起来,重新分配rebanalce。
学会处理 rebalance 问题,我们需要先搞清楚 kafaka 消费者配置的四个参数:
session.timeout.ms 设置了超时时间 是 heartbeat.interval.ms 值的3倍以上。
heartbeat.interval.ms 心跳时间间隔
max.poll.interval.ms 每次消费的处理时间
max.poll.records 每次消费的消息数
做长规定session.timeout.ms =6S汇报一次在吃饭
自己要heartbeat.interval.ms=2S汇报一次
每次吃饭的量max.poll.records=500粒
每次吃饭的时间max.poll.interval.ms=300S
1.订阅Topic的分区数Partition发生变化。
新增椅子20,所有人停止进食,从新分座位。
2.订阅的Topic个数Topics发生变化。
来了新菜品,所有人不要吃老的菜了, 我们重新排座位。
3.消费组内成员个数发生变化。例如有新的 consumer 实例加入该消费组或者离开组。
成员加入: 新人加入,所有人换座位,
组成员主动离开: 有人离开,所有人换座位,
组成员崩溃: 有人噎住了,所有人换座位,优化
1. 利用 Partition 实现并行处理
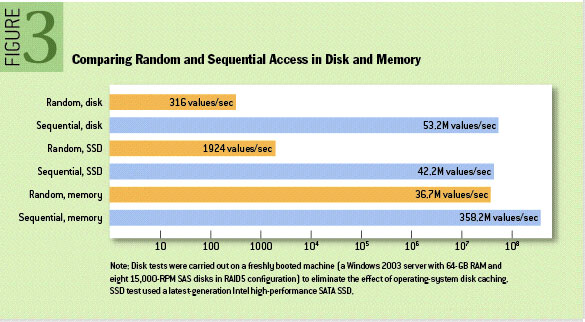
2. 顺序写磁盘
3. 充分利用 Page Cache(缓存磁盘文件), 通过操作系统的Page Cache,Kafka的读写操作基本上是基于内存的
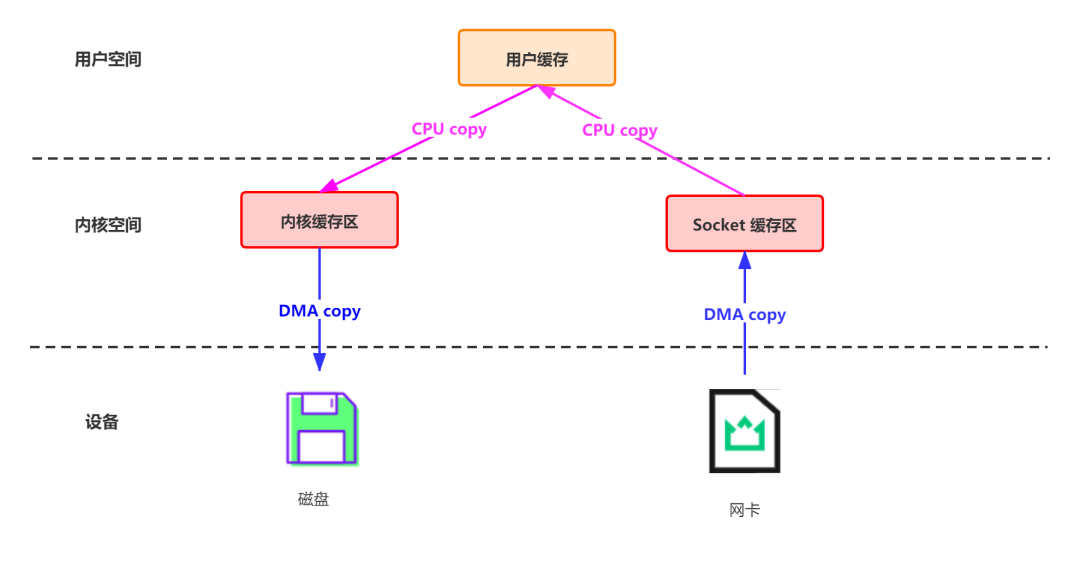
4. 零拷贝技术
5. 批处理
6. 数据压缩顺序读写
零拷贝技术
流式处理 消息队列
下一代
Pulsar
1.消息确认
kafak累计确认
Pulsar累计确认and单独确认
2.扩展性
Kafka 不是无状态的,因为每个 broker 都包含了分区的所有日志
在 Pulsar 架构中,broker 是无状态的