 lizj
lizjspark之简单数据处理
什么是spark
Spark是一个通用的分布式数据处理引擎。
通用:通用指的是Spark可以做很多事情。包括机器学习、数据流传输、交互分析、ETL、批处理、图计算等等都是Spark可以做到的。
甚至可以说,你需要用数据实现的任何事情,你都可以用Spark试试看。
分布式:指的是Spark处理数据的能力是建立在许多机器上的,是可以和分布式的存储系统对接的,是可以做横向扩展的(简单点说就是电脑越多,能力越大)
引擎:所谓引擎,说的就是Spark自己不会存储数据,它就像实体的机械引擎一样,会将燃料(对Spark来说是数据)转化成使用者需要的那种形式——例如驱动汽车,
再例如得到一个需要的目标结论。但无论如何,巧妇难为无米之炊,没数据是万万不行的。什么是sparksql
SparkSQL是Spark⽤来处理结构化数据的⼀个模块,它提供了⼀个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作⽤。
与基本的SparkRDDAPI不同,SparkSQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息。在内部,SparkSQL使用此额外信息来执行额外的优化。
有几种方法可以与SparkSQL交互,包括SQL和DatasetAPI。计算结果时,将使用相同的执行引擎,而与用于表示计算的API/语言无关。
这种统一意味着开发人员可以轻松地在不同的API之间来回切换,基于这些API提供了最自然的方式来表达给定的转换。
Hive是将Hive SQL转换成MapReduce然后提交到集群上执⾏,⼤⼤简化了编写MapReduce的程序的复杂性,由于MapReduce这种计算模型执⾏效率⽐较慢。
所有SparkSQL的应运⽽⽣,它是将SparkSQL转换成RDD,然后提交到集群执⾏,执⾏效率⾮常快!
Hive的应⽤其实就是应对不会写Java的开发⼈员但是有会写SQL的数据库语⾔提供的是MR的⼀种简化。
SparkSQL其实也就是对SparkCore中RDD的⼀种简化,⽤SQL的语⾔可以对RDD编程进⾏开发。
ps:Spark是有处理上限的(10PB),超过这个范围还是要使⽤hive来进⾏处理,hive是在100PB级别为什么要用sparksql
1. 易整合:将SQL查询与Spark程序无缝混合。
SparkSQL允许使用SQL或DataFrame的API在Spark程序中查询结构化数据。支持Java,Scala,Python和R语言。
val results: DataFrame = spark.sql(
"SELECT * FROM people")
val names = results.map(lambda p: p.name)
2. 统一的数据访问方式:以相同的方式连接到任何数据源。
DataFrame和SQL提供了一种访问各种数据源的常用方法,包括 Hive、Avro、Parquet、ORC、JSON和JDBC。甚至可以跨这些源联接数据。
spark.read.json("s3n://...")
.registerTempTable("json")
val results: DataFrame = spark.sql(
"""SELECT *
FROM people
JOIN json ...""")
3. 兼容hive:在现有仓库上运行SQL或HiveQL查询。
SparkSQL支持HiveQL语法以及HiveSerDes和UDF,允许访问现有的Hive仓库。建立session时打开hive支持即可,enableHiveSupport()
4. 标准的数据连接:通过JDBC或ODBC连接。
服务器模式为商业智能工具提供行业标准的JDBC和ODBC连接。我们可以用来干什么
1. 操作hive,由mysql同步过来的大表、存量工商表等
2. 操作hudi,线上mongo同步过来的ic等
3. 操作mysql,大表不建议直接操作
4. 操作es
5. 操作nebula
6. 操作各种格式的文件等
各种类型数据源操作后转存到其他存储工具原理是什么
SparkSQL对SQL语句的处理和关系型数据库类似,即词法/语法解析、绑定、优化、执⾏。SparkSQL会先将SQL语句解析成⼀棵树,
然后使⽤规则(Rule)对Tree进⾏绑定、优化等处理过程。Spark SQL由Core、Catalyst、Hive、Hive-ThriftServer四部分构成:
Core: 负责处理数据的输⼊和输出,如获取数据,查询结果输出成DataFrame等
Catalyst: 负责处理整个查询过程,包括解析、绑定、优化等
Hive: 负责对Hive数据进⾏处理
Hive-ThriftServer: 主要⽤于对hive的访问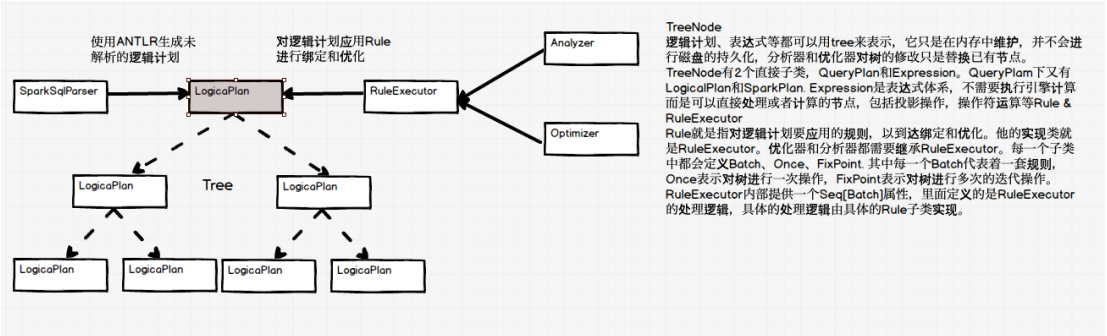
LogicalPlan-->逻辑计划
Analyzer-->分析器
Optimizer-->优化器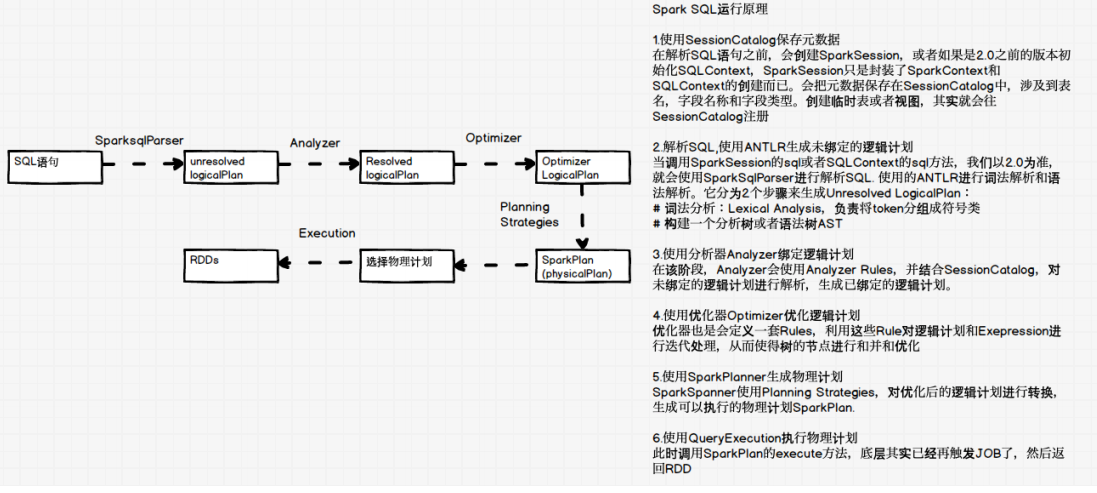
怎么使用sparksql
可以用python、scala等进行开发,这里演示scalaspark-shell

直接启动spark-shell,根据需要可以不带参数直接启动也可以指定相关配置启动,启动后进入交互界面,会默认创建
一个名为spark的sparkSession和一个名为sc的sparkContext,并且打开了.enableHiveSupport()。
可以使用spark和sc通过编码直接进行操作。
spark-shell \
--master yarn-client \
--executor-memory 16g \
--num-executors 30 \
--executor-cores 6 \
--total-executor-cores 180 \
--jars /data/227/data4/nebula_data/jars/mysql-connector-java-8.0.27.jar \
--driver-class-path /data/227/data4/nebula_data/jars/mysql-connector-java-8.0.27.jar
示例:
1. 操作hive:
val dfHive: DataFrame = spark.sql("select * from ic_base.company_industry limit 100").persist(StorageLevel.MEMORY_AND_DISK_SER)
dfHive.show(10, 32)
dfHive.count
dfHive.printSchema
dfHive.createOrReplaceTempView("tmp")
spark.sql("insert into table select * from tmp")
2. 操作hudi:
val dfHudi: DataFrame = spark
.read.format("org.apache.hudi")
.load("hdfs://emr-header-1.cluster-210983:9000/user/collie/warehouse/ods/ic.db/company_branch/*")
# .option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL)
# .option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, commitTime)
# .option(DataSourceReadOptions.INCR_PATH_GLOB_OPT_KEY, "/year=2020/month=*/day=*")
dfHudi.write.format("org.apache.hudi").mode(SaveMode.Append).save("path")
3. 操作mysql:
val dfMysql1: DataFrame = spark
.read
.jdbc(url,table,column,lowerBound,upperBound,numPartitions,new Properties())
val dfMysql2: DataFrame = spark
.read
.format("jdbc")
.options(Map("url" -> properties.getProperty("jdbc.url"),
"dbtable" ->
f"(SELECT commit_time FROM nebula_commit_time where type = 'dwm' and table_name = '$table' order by update_time desc) nebula_commit_time"))
.load()
dfMysql1
.write
.mode(SaveMode.Append)
.jdbc("jdbc:mysql://10.8.6.87:3801/utn_ec?user=root&password=root123","tb_ebusiness_data_b",new Properties())
4. 操作各种文件
val df: DataFrame = spark
.read
.format("csv")
.option("inferschema", "false")
.option("header", "false")
.option("quote", "\'")
.option("encoding", "utf8")
.load(path)
.toDF("_id", "branch_company_name_digest", "company_name_digest", "update_time", "n_company_status")
val df: DataFrame = spark
.read
.json
.load("path")
df.write
.mode(SaveMode.Append)
.option("quoteAll", value = true)
.csv(csvPath.concat("base_tmp"))
df.write
.mode(SaveMode.Append)
.json("path")
.parquet("path")spark-submit
编写程序后打成jar包(包含依赖和不包含依赖),通过spark-submit将任务提交到集群上执行,此处结束maven方式和工件方式
spark-submit \
--deploy-mode cluster \
--jars jars/nebula-spark-connector-3.0.0.jar \
--driver-class-path jars/nebula-spark-connector-3.0.0.jar \
--class com.pa.v3.Update azkaban/equity-penetration.jar \
azkaban/updateDwmNebula.properties链接
Spark SQL 和 DataFrames - Spark 2.4.7 文档 (apache.org)
GitHub - apache/spark: Apache Spark - A unified analytics engine for large-scale data processing